Reinforcement Learning from Human Feedback (RLHF)
Reinforcement learning (RL) is a type of machine learning in which an agent learns to behave in an environment by trial and error. The agent receives feedback from the environment in the form of rewards and punishments, which it uses to update its policy, or strategy for taking actions.
In traditional RL, the reward function is defined by the designer of the environment. However, in some cases, it may be difficult or impossible to define a reward function that accurately captures the desired behavior of the agent. In these cases, RLHF can be used to train the agent from human feedback.
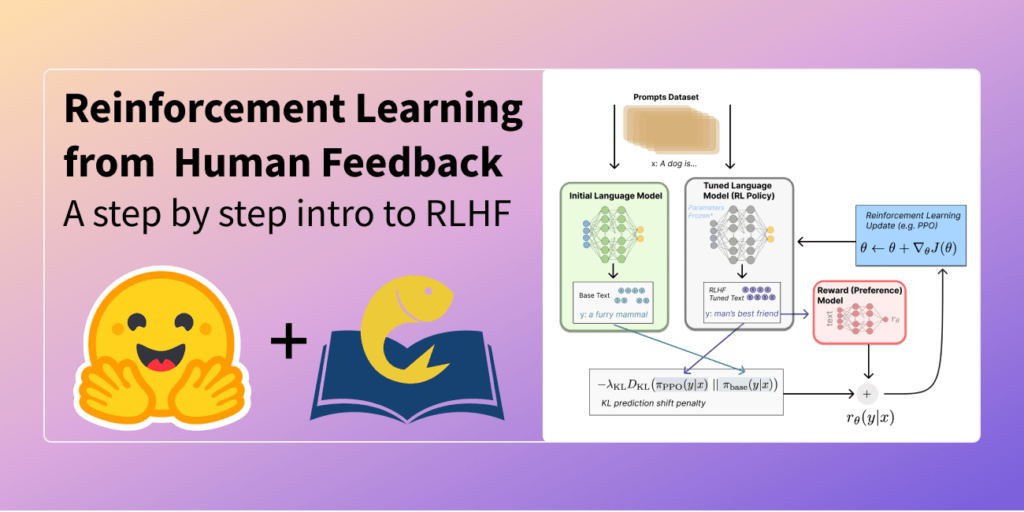
RLHF works by first training a “reward model” that predicts the human’s preferences for different outputs. This model is then used as a reward function to train the agent using RL.
There are several advantages to using RLHF. First, it allows the agent to learn from human preferences, which can be more accurate than a manually-defined reward function. Second, RLHF can be used to train agents in environments where it is difficult or impossible to define a reward function. Third, RLHF can be used to train agents that are sensitive to human preferences, such as language models and chatbots.
However, there are also some challenges associated with RLHF. One challenge is that it can be difficult to collect enough human feedback to train a reliable reward model. Another challenge is that RLHF can be computationally expensive, as it requires both training the reward model and training the agent using RL.
Despite these challenges, RLHF is a promising technique for training agents from human feedback. As the technology continues to develop, RLHF is likely to become more widely used in a variety of applications.
Here are some examples of how RLHF is being used today:
- Chatbots: RLHF is being used to train chatbots that are more sensitive to human preferences. For example, a chatbot could be trained to be more polite or more informative, depending on the feedback from users.
- Language models: RLHF is being used to train language models that generate text that is more aligned with human preferences. For example, a language model could be trained to generate text that is more creative or more factual, depending on the feedback from users.
- Robotics: RLHF is being used to train robots that interact with humans in a safe and effective way. For example, a robot could be trained to avoid bumping into people or to respond to human commands in a timely manner.
As RLHF technology continues to develop, it is likely to be used in a wider variety of applications. This could include training agents to play games, to control medical devices, or to perform other tasks that require human-like interaction.
Leave a Reply